- Published on
Static Code Analysis – The Underrated Ally
- Authors

- Name
- Aleksandar Zeljković
- @a_zeljkovic
In our efforts to achieve CI and CD, we are trying to get feedback about the application as fast as possible. We are trying to get feedback from automated tests, logging and reporting frameworks, infrastructure monitoring tools, analytics tools, etc. Some of these mechanisms are complex to set up, expensive, and very often require some additional staffing. In all those fusses, development teams are very often overseeing one major component which is able to deliver huge benefits at a decent price – static code analysis!
What is static code analysis?
Static code analysis (hereinafter SCA) is, at simplest, the process of code examination without code execution. This process is done by the tool, which has a set of (customizable) rules that are applied during code scan. The scan process is searching for parts of code where issues (defined through the ruleset) occur. Finally, the output of this process is a report which contains problems and vulnerabilities found during scanning. Above is described one SCA scan cycle where we can recognize 4 main components of the SCA process:
- Source code
- SCA tool
- Coding rules
- Scanning report
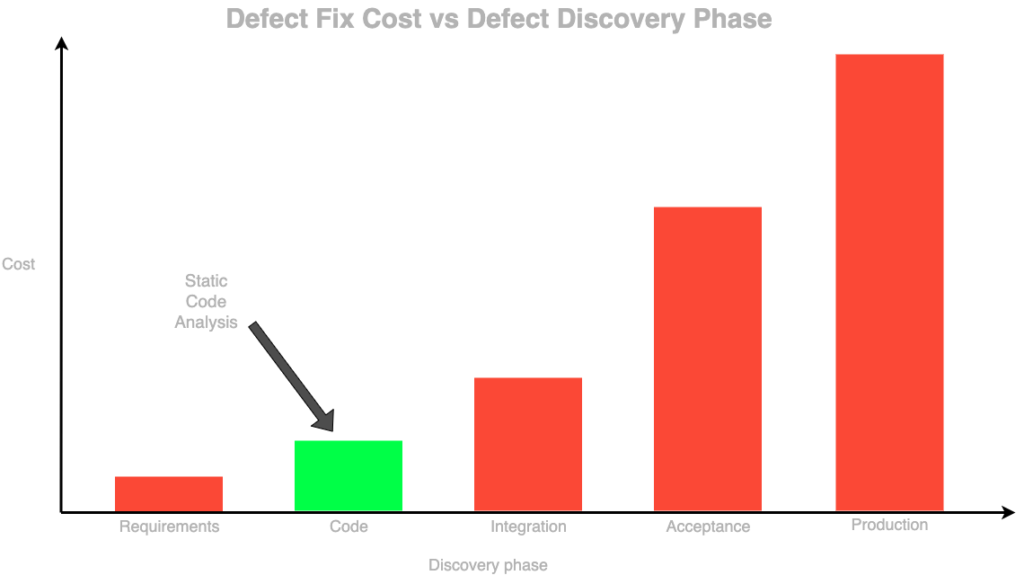
Be aware that more complex SCA tools that are used in teams with a large codebase very often require significant computing power to process the code, so sometimes this can be considered the fifth component. Either you choose managed service or an on-premise solution, the price of this component should not be overseen in the process of solution evaluation. On the other side of the complexity spectrum, there are simple SCA solutions and one example is a simple code linter. The main advantage of SCA is the early discovery of different types of defects which, if propagated deep into the development process, can be extremely expensive to fix, or even worse, can cause a lot of damage to your product and reputation.
Types of defects caught by static code analysis
Some techniques used in the SCA process are:
- Data Flow Analysis – this technique is analyzing the flow of data through the program, trying to identify issues related to data usage and lifecycle (creation, definition, types, destruction, etc.)
- Control Flow Analysis (Graph) – interpretation and analysis of all existing paths of program execution
- Taint Analysis – identification of elements that can access or change the data within a system to perform malicious activities
- Lexical Analysis – Tokenization of code in order to find code parts that are subject to manipulation
Types of defects that can be found via the SCA process are:
- Code issues
- Code duplication
- Low test coverage
- Formating recommendations
- Coding standard violations
- Security vulnerabilities
- Cyclomatic complexity
Other advantages which SCA tools provide are the ability to fully customize scanning rules and parameters, visualization dashboards for a better quality overview, estimation of the time necessary to fix found issues, etc.
Benefits and limitations of static code analysis
SCA provides numerous benefits:
- Full code coverage – SCA tools let you completely define the code coverage. You can exclude specific files, file types, and languages that you want to avoid. Otherwise, if you want your complete codebase to be covered, it will not make a significant difference in configuration effort or execution time, so you won’t be forced to compromise.
- Execution speed and stability – unlike some other automated testing techniques, SCA is fast and doesn’t have stability problems, so you won’t have to deal with flakiness, configuration, data issues, etc.
- Significant reduction of code review time – developers can shift focus from rules which are already covered by SCA and pay attention to logic and intention of the written code
- Early detection of errors – if SCA is properly placed in the CI/CD pipeline, the developer is aware of issues in his code before it is merged to the main branch, which enables him to fix the code early and at a low cost
- Stable code quality over time – constant usage of SCA enables teams to be confident in their code, at least the aspects which they defined through the SCA rules
On the other side, development teams must be aware of certain pitfalls of SCA:
- Tool misconfiguration – poorly defined rulesets can cause blocked development and stressed development teams due to inapplicable rules
- Late SCA implementation – if SCA is introduced late in the development process, a large number of issues can cause stressed and frustrated dev teams if the fix process is not managed properly
- False positives/negatives – SCA can produce false positive or negative results in certain situations, for example:
- Some code implementations can be valid or invalid in different contexts
- External code/libraries cannot be analyzed by the tool
- The tool does not understand the code intent
- Rules quality – a scan is as good as rules defined, so if a proper ruleset is not created at the beginning, it can cause unfulfilled expectations
Tools selection criteria
As with any other testing/development tool, it is very important to properly evaluate the SCA tool before making a final decision. To make the right choice, a team must be able to answer the following questions:
- Which programing language/languages tool needs to support
- IDE integration
- Reporting and metrics capabilities
- CI/CD integration
- Supported types of issues and vulnerabilities
- User interface quality
- Ability to customize scanning rules
- Tool price
It is highly recommended to do a detailed tool evaluation before full implementation. A small but representative project should be picked for this purpose and all potential users and roles should give their input. Remember, the SCA tool is a tool that you’ll use on every pull request or even more often, so you want it to help you with your quality and not to take time and bring frustration.
Conclusion
If you’re looking for a way to increase the quality of your code, shift security left, and maintain high coding standards over an extended period of time, then look no further – static code analysis is here to help. It will enable your team to catch (potential) bugs very early in the development lifecycle, lower the stress and fix costs significantly. It will also let developers do better code reviews since they will not have to deal with certain types of issues that will be taken over by the SCA tool.
Also, don’t forget one very important fact: we are living in the everything-as-code era. This means that we don’t only have application logic in the form of code, but we also keep databases, infrastructure, tests, configurations, YAMLs, JSONs, Dockerfiles, etc. in the version control system. This increases the value of static code analysis significantly since modern tools provide support for a lot of different code types and syntaxes. This is why static code analysis should be a practice of every team that is striving for rapid delivery and it should definitely be your ally on the road to software excellence.
(Note: This article was originally published in Quality Matters magazine – issue number 12)